

この記事は「アイリスコープ feat. 紡乃世詞音」の調声解説記事です.
通販はこちらから!

使用したもの
- A.I.VOICE2 紡乃世詞音
- A2Sync (A.I.VOICE2で歌ってもらうツール)
- 仮歌 ※CeVIO AI 双葉湊音さんを使用
- DAW ※Studio One を使用・お好みで良い
- Python実行環境 ※Google Colabなど何でもよい
Step 0: 曲と仮歌を作る
このあたりは省略します.アイデアが形になるまで格闘しましょう.
仮歌のデータをwavで書き出しておきます.このデータをもとに紡乃世さんの調声を行うため,歌声合成ソフトで仮歌を作成する場合は調声を行っておきましょう.
Step 1: 歌唱シーケンスファイルを用意する
始めにA2Syncで読み込める形式の歌唱シーケンスファイルを用意します.
A2Syncに対応している形式は .ust .vsqx .musicxmlです.
今回は双葉湊音さんに仮歌をお願いしたため,.musicxmlを用います.
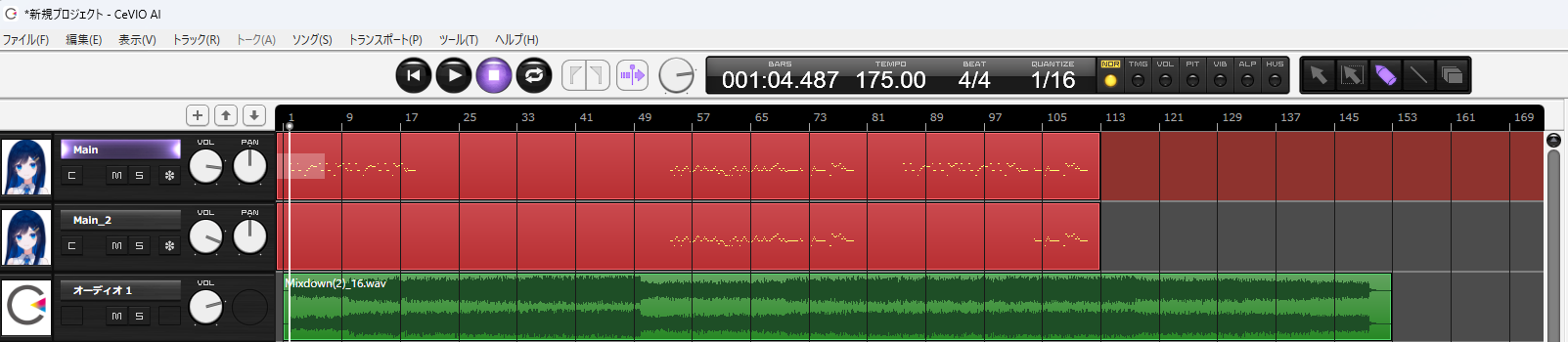
Musicxmlの書き出しはトラックのリージョン(赤い所)を右クリックし,エクスポート>MusicXMLの書き出し から行えます.ここで書きだしたMusicXMLの拡張子が .xml になっているため, .musicxmlに直しましょう(1敗).
また,あまり長いシーケンスファイルだとA2Syncの動作が上手くいかない可能性があるため,楽曲のセクションごとにファイルを分けて書き出すと良いでしょう.
Step 2: A2Syncで紡乃世さんに歌ってもらう
Step 1で書き出した .musicxml を読み込んで紡乃世さんに歌ってもらいましょう.
A2Syncの使い方は,制作者(神)のアウクシさんの以下の動画を見てください.

実行中はPCの操作ができないのでWinの仮想環境か別のWin機を用意すると良いでしょう.(A.I.VOICE2もAPIを公開してほしいね)
プロジェクトファイルの保存場所がオンラインストレージだと失敗するので注意しましょう(1敗).
Step 3: タイミングを調整する
A2Syncが出力したWAVファイルをDAWで読み込んで発音タイミングを調整します.
このとき,仮歌の発音タイミングと合わせるように弄っていきます.
タイミング調整の指針として,母音の発音タイミングが楽譜上の発音タイミングと一致するように修正していくと良いでしょう.CeVIO AIのTMGが良い例ですが,日本語の歌の場合,母音の発音タイミングが楽譜上の発音タイミングと一致しており子音はそれより前の時刻に配置されていることがわかります.
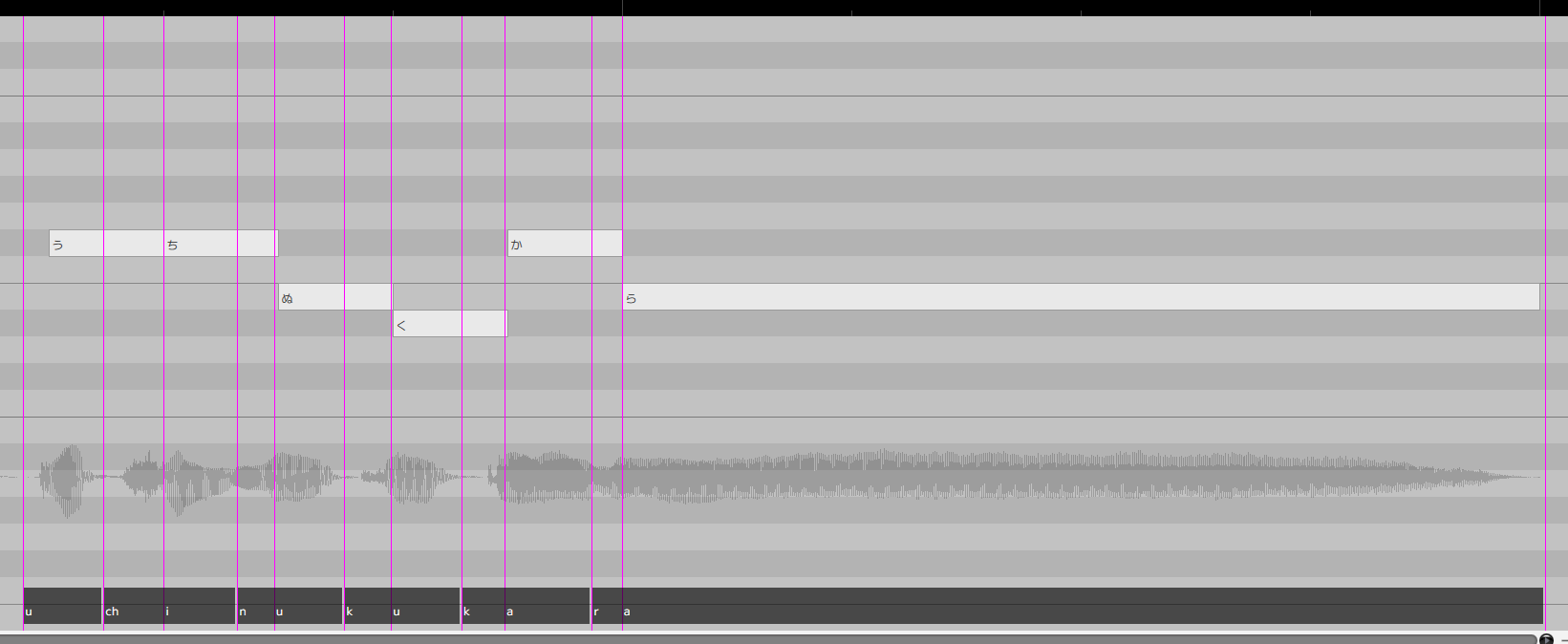
日本語テキスト音声合成ソフトでは,モーラが調声の最小単位であることが多い一方,歌声合成ソフトでは音素が最小単位であることが多いため,このギャップを現時点では手動で埋める必要があります.
タイミング調整に使用するツールはカットとタイムストレッチで,その優先度はカット>タイムストレッチです.
Studio OneやCubaseでは,タイムストレッチのアルゴリズムにzplane社のélastiqueアルゴリズムを採用しているため,波形の伸縮時の劣化は比較的抑えられていますが,それでも気になるレベルで音声の品質が劣化するためタイムストレッチの使用は最小限にしましょう.
Step 4: ピッチと声質を調整する
タイミングを調整したWAVファイルと仮歌のファイルを用意します.
ここでの主目的は仮歌のピッチカーブを紡乃世さんになぞってもらうことです.
歌ボの場合は,VocalShifter等を使用してピッチを調整することが多いと思いますが,手書きでピッチの調整を行うのは大変しんどいため別の手法を用います.
VocalShifterではピッチを変換した音声の再合成にWORLDを用いていますので,これをスクリプトベースで使用することを考えます.
Pythonを利用して簡単に実装したものがこちらになります.
ここでは source.wavが紡乃世さんの歌声ファイル,guide.wavが仮歌の音声ファイルを表しています.
import pyworld as pw
import soundfile as sf
import numpy as np
# 各特徴量を抽出する関数
def extract_parameters(wav_file):
x, fs = sf.read(wav_file)
if x.ndim > 1:
x = np.mean(x, axis=1)
_f0, t = pw.dio(x, fs)
f0 = pw.stonemask(x, _f0, t, fs)
sp = pw.cheaptrick(x, f0, t, fs)
ap = pw.d4c(x, f0, t, fs)
return f0, sp, ap, fs
# 分析結果の長さの微妙な不一致をごまかす関数
# ほんとはDTWとかMASをやってもいい
def match_frame_lengths(f0, sp, ap):
min_length = min(len(f0), sp.shape[0], ap.shape[0])
f0 = f0[:min_length]
sp = sp[:min_length, :]
ap = ap[:min_length, :]
return f0, sp, ap
# 再合成して保存する関数
def synthesize_and_save(f0, sp, ap, fs, filename):
f0, sp, ap = match_frame_lengths(f0, sp, ap)
y = pw.synthesize(f0, sp, ap, fs)
sf.write(filename, y, fs)
# 特徴量を抽出
f0_source, sp_source, ap_source, fs_source = extract_parameters('source.wav')
f0_guide, sp_guide, ap_guide, fs_guide = extract_parameters('guide.wav')
# 組み合わせを変えて再合成
combinations = [
(f0_guide, sp_source, ap_source, fs_source, 'guide_source_source.wav'),
(f0_guide, sp_source, ap_guide, fs_source, 'guide_source_guide.wav'),
(f0_guide, sp_guide, ap_source, fs_source, 'guide_guide_source.wav')
]
# 合成して保存
for f0, sp, ap, fs, filename in combinations:
synthesize_and_save(f0, sp, ap, fs, filename) WORLDでは,音声ファイルから分析した音声の特徴量を元に音声を再現することで音声を再合成しています.
再合成の際に弄ったピッチカーブを与えることで出力される音声のピッチを変更しているわけです.
WORLDは,音声の特徴量として基本周波数(f0),スペクトル包絡(sp),非周期性指標(ap)を扱います.
それぞれピッチ・音色・声のかすれを表していると簡単に思ってもらえれば良いです.
このスクリプトでは,上記のうち,基本周波数(f0)を除く2種の特徴量を紡乃世さんと双葉さんの声の間でシャッフルして音声を再合成しています.
このようにすることで仮歌のピッチに追従し,紡乃世さんの歌声っぽい声質で歌う音声を獲得しています.
Step. 5 歌声の破綻を修正する
Step. 4で獲得した音声をDAW上で再生してみると,音声が破綻している箇所が確認できると思います.
ここでは,Step. 3 と Step. 4 で獲得した音声ファイルをつなぎ合わせて破綻の少ない音声を得ます.
Step. 4の音声の破綻個所をStep. 3の音声で差し替えてあげると良いでしょう.
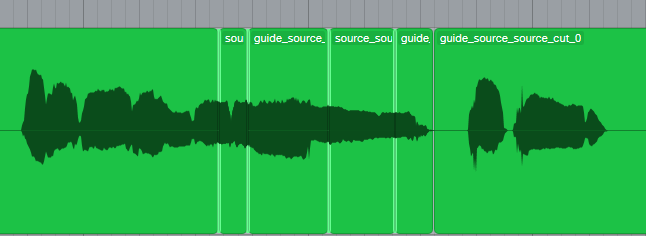
この際に以下のように波形の振幅が0になる地点(ゼロクロスポイント)でつなぐと良い結果が得やすいです.
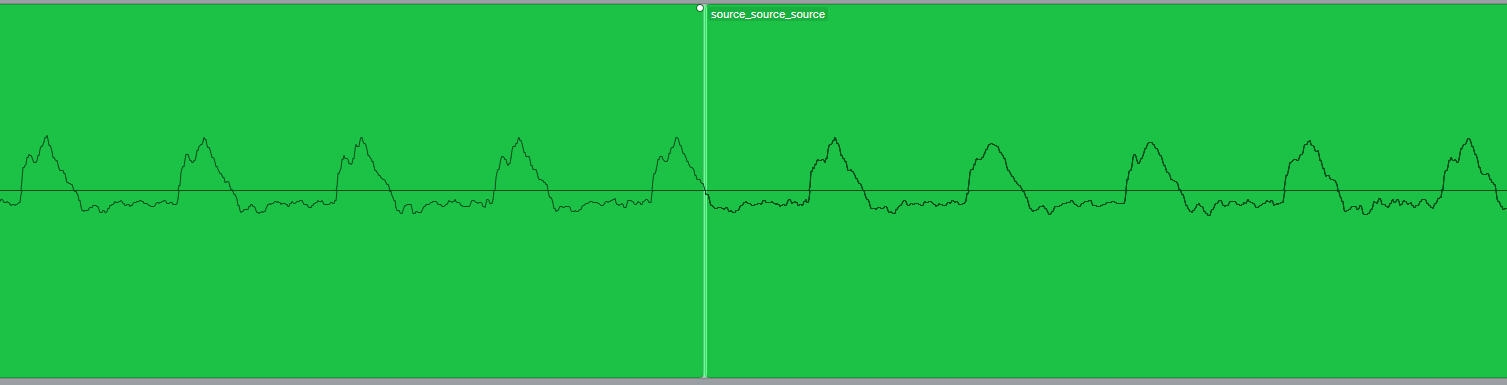
今回は追加でiZotope RXなどでスペクトログラムの修復も行いました.
Step. 6 MIXへ
ジャンルによるため,あまり参考になる所はないので共通部分を簡単に
- OTTを挿そう
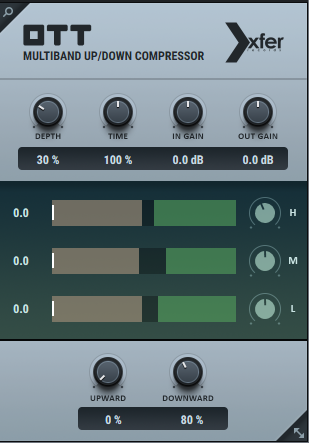
合成音声の場合,Depth20~30%ぐらいで掛けると,その後の処理がしやすくなります.
- Dynamic EQ で均す
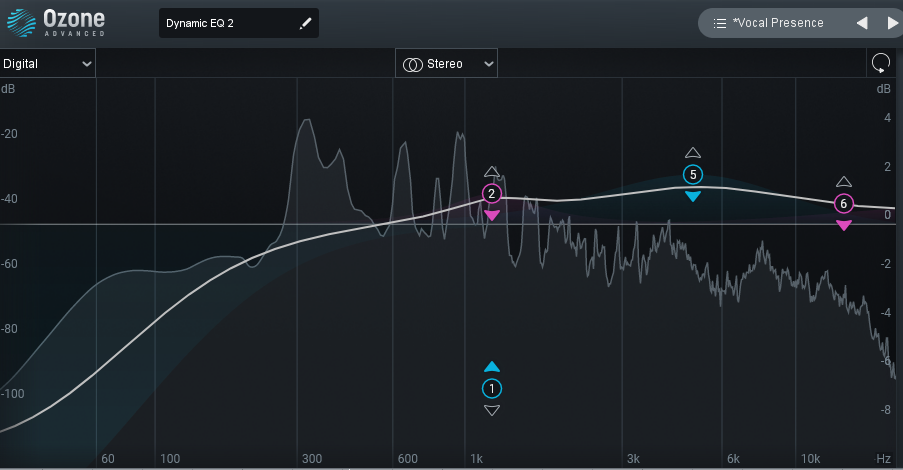
特に歌ボの場合,歌声と周波数特性が違ってMIXがしにくいので無理やり特性を近づけるのに有用.
- Distortionで馴染ませる
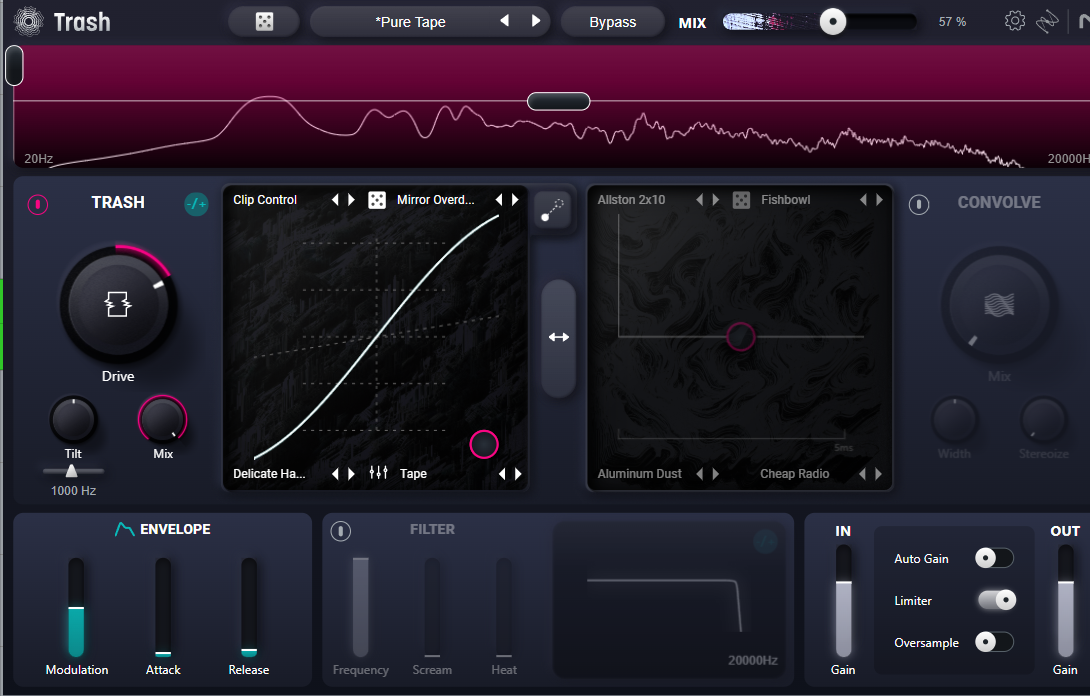
ちょっとだけ歪ませると他の音との混ざりが良くなる.これは全楽器共通.
終わりに
最近の歌ボの知見があまり見つからないので,今回の制作でやったことを全部書いてみました.
可食部だけお持ち帰りいただけると幸いです.
各ステップの比較用音声
仮歌→A2Sync出力→タイミング調整後→ピッチ&声質調整後→破綻の修正後→ミックス後Vo単体→2Mix